Wasserstein-GAN
PyTorch implementation of Wasserstein GAN by Martin Arjovsky, et al. on the MNIST dataset.

Loss and Training
The network uses Earth Mover’s Distance instead of Jensen-Shannon Divergence to compare probability distributions.
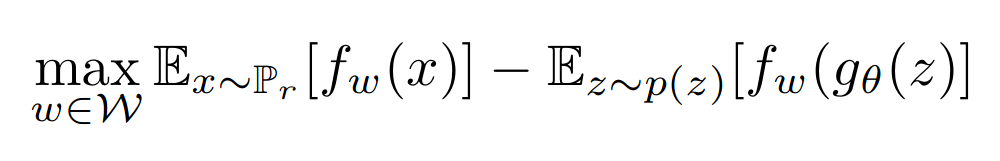
I modeled the generator and critic both using Multi Layer Perceptrons to verify some of the paper’s claims. The log(D(x)) trick from the original GAN paper is used while training. The hyperparameters used are as described in the paper. After a few hundred epochs, this was the loss curve.
